
Scrape爬取小说内容

Scrape爬取小说内容
Yusialone安装 twisted 与 scrapy
1 | pip install twisted |
自订目录,安装 scrape 配置文件
1 | d: |
进入 pycharm,打开目录
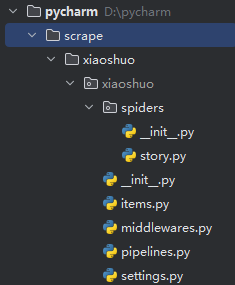
编写 story.py
1 | import scrapy |
编写 pipelines.py
1 | class XiaoshuoPipeline: |
注释 settings.py
1 | # Override the default request headers: |
1 | ROBOTSTXT_OBEY = True |
编写开始文件 start.py,注意路径
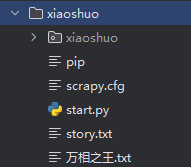
1 | from scrapy import cmdline |






评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果







