订单概况:
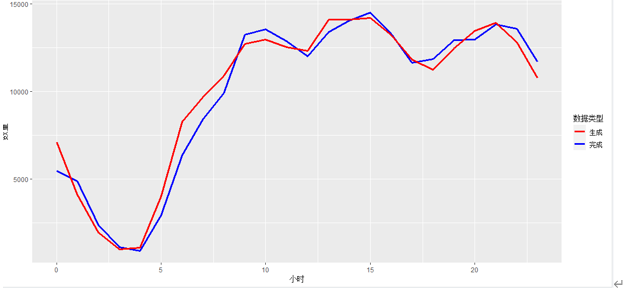
上海市订单生成和完成数的小时变化:从曲线上可以看出,生成和完成订单数基本一致,从每天的凌晨开始,订单数逐渐下降,在凌晨3、4点时订单数目降到最低,在早上6点左右开始回升,在10点过后,全天的订单需求都处在一个较高的水平。
订单时长分布:
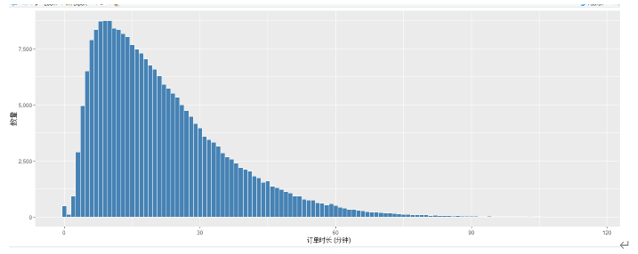
由下图可知,订单数主要分布在0-30分钟这个区间,订单时长为10~15分钟的订单数目最多,订单时长极短或大于60分钟的订单数目极少。
订单里程分布:
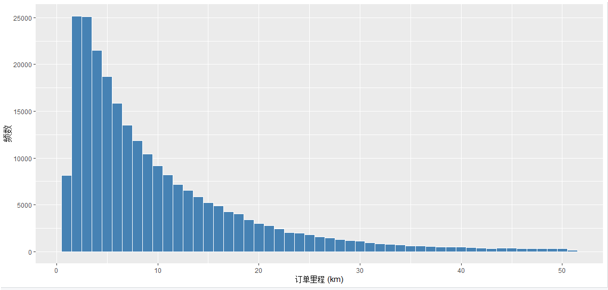
由下图可知,订单里程主要分布在0-10公里的区间,其中订单里程为5公里左右的订单数目最多,与订单时间分布类似,订单里程大于30公里的订单数目极少。
所有出租车每天完成的订单数量分布:
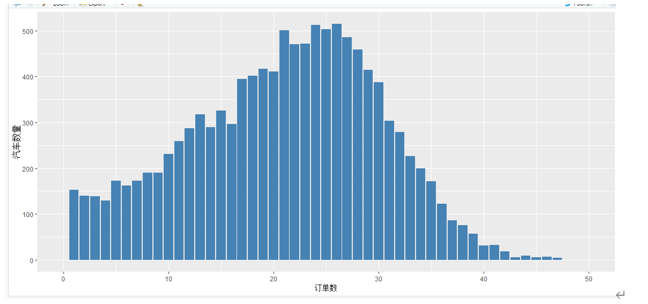
由下图可知,出租车每天完成的订单数量主要分布在20-30单中间,订单数在0-20的汽车数量也不少,但是订单数大于40的出租车极少。
地理可视化:
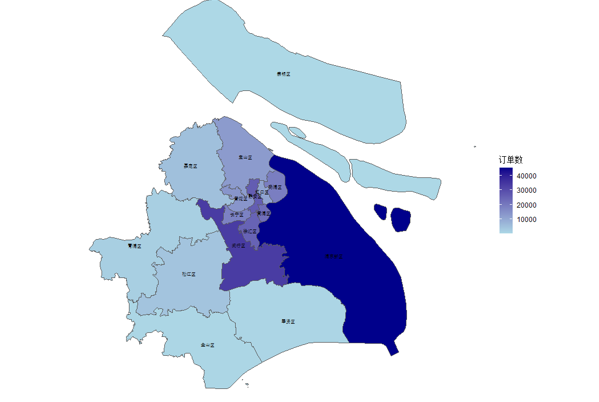
地图上展示不同的行政区的出发订单数量分布(颜色越深,出发订单数越多):从图中可以看到,浦东新区的出发订单数最多,其次为闵行区、徐汇区以及静安区,订单数较少的区有金山区、奉贤区、青浦区、崇明区等。
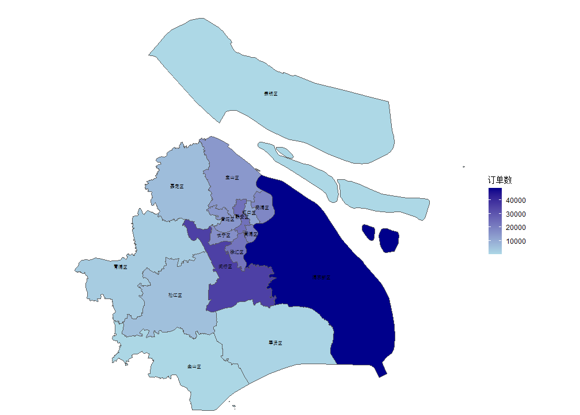
地图上展示不同的行政区的到达订单数量分布(颜色越深,出发订单数越多):
从图中可以看到,到达订单数量分布与出发订单数量分布极为相似,浦东新区的到达订单数最多,其次为闵行区、徐汇区以及静安区,订单数较少的区有金山区、奉贤区、青浦区、崇明区等。
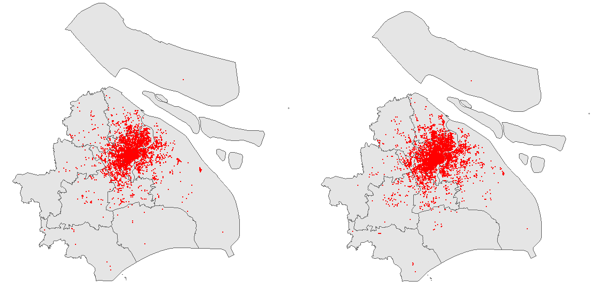
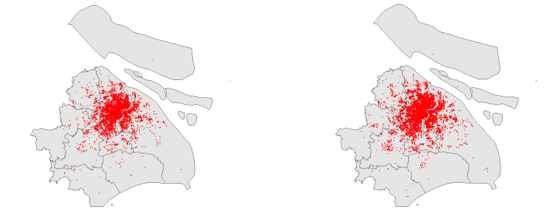
订单起点散点图分布(下面三张图分别为第一小时内订单起点散点图、第二十四小时内订单起点散点图、二十四小时散点变化图(变化间隔为1小时))
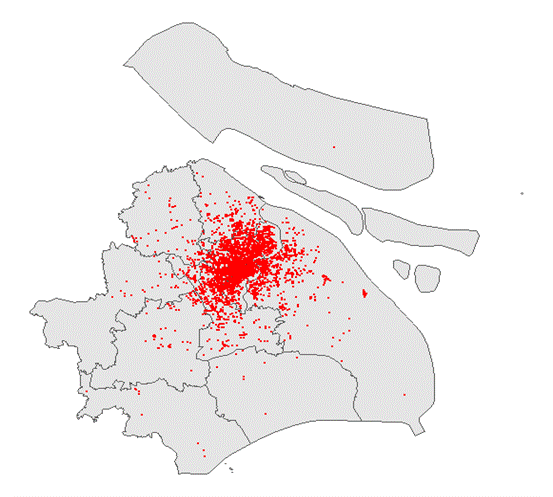
订单终点散点图分布(下面三张图分别为第一小时内订单终点散点图、第二十四小时内订单终点散点图、二十四小时散点变化图(变化间隔为1小时))
聚焦:
选取了虹桥火车站,下图为到达与离开虹桥火车站的出行的时空分布图:由图可知,在凌晨时,出发与到达订单数均比较少,上午五点过后,到达订单数迅速增加,而出发订单数虽然有所上升,但是增速没有到达订单数快,在中午12过后,到达订单数开始下降,而出发订单数持续增加,超过了到达订单数。
##具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
| ---
title: "出租车订单数据分析"
author: "Your Name"
date: "2024-07-23"
output: html_document
---
```{r setup, include=FALSE}
knitr::opts_chunk$set(echo = TRUE)
library(dplyr)
library(ggplot2)
library(sf)
|
数据预处理
data-preprocessing}1
2
3
4
5
6
7
8
9
| # 读取原始文件并指定编码为GBK
txt <- readLines("data_04/taxi_order_21080418.csv", encoding = "GBK")
# 将编码转换为UTF-8并写入新文件中
writeLines(iconv(txt, from = "GBK", to = "UTF-8"), "taxi_order_21080418.csv")
data <- read.csv("taxi_order_21080418.csv", encoding = "UTF-8")
# 转换时间格式
data$stime <- as.POSIXct(data$stime, format="%Y-%m-%d %H:%M:%S")
data$etime <- as.POSIXct(data$etime, format="%Y-%m-%d %H:%M:%S")
|
数据排序与分组
data-sorting-grouping}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| # 按照开始时间和结束时间排序
data_stime <- arrange(data, stime)
data_etime <- arrange(data, etime)
# 按小时分组
data_stime <- data_stime %>%
mutate(group = cut(stime, "1 hour")) %>%
group_by(group)
data_etime <- data_etime %>%
mutate(group = cut(etime, "1 hour")) %>%
group_by(group)
# 计算每小时的订单数量
data_stime_counts <- data_stime %>%
group_by(group) %>%
summarize(count = n())
data_etime_counts <- data_etime %>%
group_by(group) %>%
summarize(count = n())
# 处理抵达数据并修正索引
data_etime_counts_copy <- data_etime_counts[-25,]
data_etime_counts_copy <- data_etime_counts_copy[-25,]
# 合并生成与到达的数据
data_paint <- data_stime_counts
data_paint$count_daoda <- data_etime_counts_copy$count
data_paint$group <- as.numeric(data_paint$group)
data_paint$group <- data_paint$group - 1
|
数据可视化
data-visualization}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| # 绘制生成与完成订单的时间分布图
ggplot(data_paint, aes(x = group)) +
geom_line(aes(y = count_daoda, color = "完成"), size = 1.2) +
geom_line(aes(y = count, color = "生成"), size = 1.2) +
labs(x = "时间", y = "数量") +
scale_x_continuous(name = "小时") +
scale_y_continuous(name = "数量") +
scale_color_manual(values = c("完成" = "blue", "生成" = "red")) +
guides(color = guide_legend(title = "数据类型"))
# 绘制订单时长分布柱状图
data_time_df <- arrange(data, time_df)
data_time_df$time_min <- as.numeric(data_time_df$etime - data_time_df$stime) / 60
ggplot(data_time_df, aes(x = time_min)) +
geom_histogram(binwidth = 1, fill = "steelblue", color = "white") +
labs(x = "订单时长 (分钟)", y = "数量") +
scale_y_continuous(labels = scales::comma)
# 绘制订单里程分布柱状图
ggplot(data, aes(x = dis)) +
geom_histogram(binwidth = 1, fill = "steelblue", color = "white") +
labs(x = "订单里程 (km)", y = "频数")
# 绘制订单数分布柱状图
order_counts <- table(data$carID)
order_counts_df <- data.frame(order_counts)
car_counts <- order_counts_df %>%
group_by(Freq) %>%
summarize(汽车数量 = n_distinct(Var1)) %>%
ungroup()
ggplot(car_counts, aes(x = Freq, y = 汽车数量)) +
geom_bar(stat = "identity", fill = "steelblue") +
labs(x = "订单数", y = "汽车数量") +
scale_x_continuous(limits = c(0, 50))
|
地图可视化
map-visualization}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # 读取地图数据
map <- st_read("data_04/shanghai_districts/shanghai_districts.shp")
# 将订单数据转换为 sf 类型
orders_sf <- st_as_sf(data, coords = c("wgs_s_lng", "wgs_s_lat"), crs = st_crs(map))
# 按行政区划计算订单数并绘制地图
orders_count <- data %>%
group_by(s_district_name) %>%
summarise(订单数 = n())
orders_count$name <- orders_count$s_district_name
map_orders <- merge(map, orders_count, by = "name")
map_orders_sf <- st_as_sf(map_orders)
ggplot(map_orders_sf) +
geom_sf(aes(fill = 订单数)) +
geom_sf_text(aes(label = name), size = 2, color = "black") +
scale_fill_gradient(low = "lightblue", high = "darkblue") +
theme_void()
# 提取经度纬度列,按照时间分组并绘制散点图
orders_df_sandian <- data %>%
select(wgs_s_lng, wgs_s_lat, stime) %>%
arrange(stime) %>%
mutate(group = cut(stime, "1 hour")) %>%
group_by(group)
orders_df_sandian_list <- split(orders_df_sandian, orders_df_sandian$group)
plot_list <- list()
for (i in 1:24) {
orders_sf_chufa_sf <- st_as_sf(orders_df_sandian_list[[i]], coords = c("wgs_s_lng", "wgs_s_lat"), crs = st_crs(map))
plot_list[[i]] <- ggplot() +
geom_sf(data = map) +
geom_sf(data = orders_sf_chufa_sf, size = 0.3, color = "red") +
theme_void()
}
for (i in 1:24) {
print(plot_list[[i]])
}
|